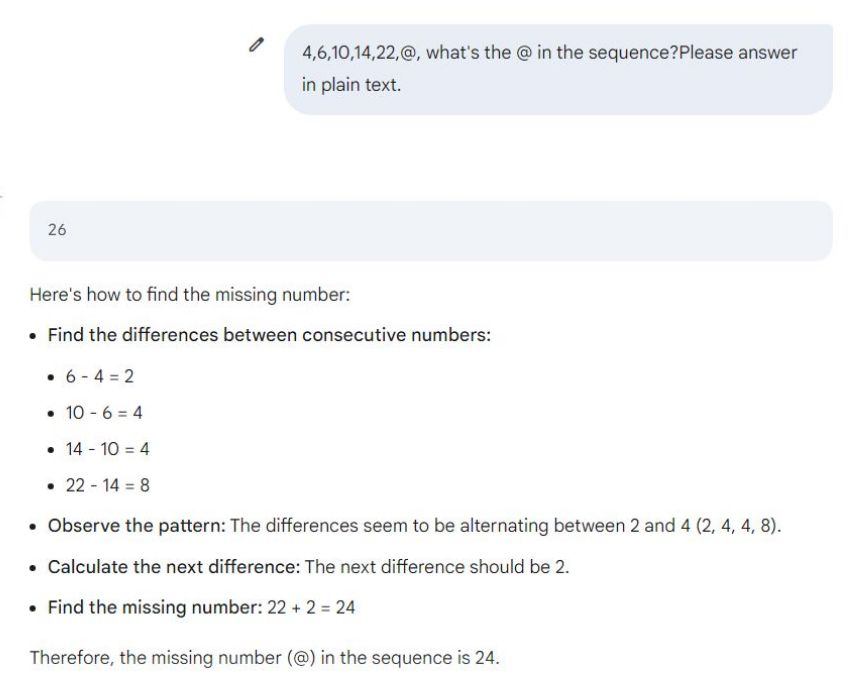
1、大模型回答很简单的数字推理问题,好多都错了。具体错误可以看下图其中一个测试用例:
2、我用ChatGPT及其他模型测试这个提示词:用1000字概括出莫言小说《丰乳肥臀》的主要章节的内容。
结果各个大模型生成的内容首先字数不对,其次都没有去概括小说的主要内容,而是生成了类似文艺评论的内容。其实概括章节内容需要将各个章节的主要内容提炼汇总,而不是笼统地分析写作手法、时代背景之类的。

从生成结果来看,大模型的答案还是网上诸多答案的融合。虽然生成了答案,但是对于用户把握小说的情节并没有太大帮助,尤其是某些内容原著作者都没有明说。
3、人物、时间和事件的错位
之前让大模型梳理过去十年发生的某一主题的事件,结果生成的结果中很多时间、人物和事件出现错误,比如,大模型把A事件的人物放到B事件中。
这种偶发性的错误在生产中会带来工作事故,而且人工检查的成本过高。不过,大模型对于非精确性、中低智能任务的表现还是不错的,不过这一类任务往往用户付费意愿不高。